LSPS Documentation
Queries serve to request data from the underlying LSPS database or an external database.
You can define two types of queries:
Both query types are defined in the query definition file.
A standard query returns shared Records from the database. and is defined in the Expression Language. It is simple to define but its possibilities are restricted.
A standard query defines the following properties:
Single value: amount of the returned entries
If true, only the first entity is returned. If false, all entities are returned.
Distinct: whether to return only unique entities
If enabled, identical entities result in a sole entity in the returned data.
Public: availability of the query in Module imports.
If not public, importing Modules cannot use the query.
toLowerCase(), toUpperCase(), trim(), length(), substring(): no other functions can be used in the query condition:getDayOfMonth(book.published)=5 as query condition is invalid since the getDayOfMonth() function does not define its translation to SQL.toLowerCase(b.Author)=="joseph heller" is a valid query condition since the toLowerCase() function does define its translation to SQL.* and ? wildcards. Note that it is not possible to escape these characters. If required, consider using Native Queries instead. Important: the condition is interpreted into SQL and the interpretation does not fully correspond to its Expression Language interpretation mainly due to the fact that the
nullvalue is not considered a legitimate value in databases. Hence,!= nullis interpreted asis not nulland== nullis interpreted asis null. For example, if you use the conditionx != trueas a query condition, if x is null in the database, it will not be included in the results.
Join Todo List: allows to create a join to a list of to-dos which are ALIVE
If the shared Record has a relationship to the human::Todo record, you can use the join to get the to-dos related to your Record, typically, in the Condition. This mechanism makes up for the absence of the direct access to the to-do database tables.
new TodoListCriteria( person -> p, includeSubstituted -> true, includeAllocatedByOthers -> true )
Paging: the query returns the number of entities defined by the Result size starting from the Start Index position.
If the start index and result size are both null, the query returns all results: no paging is applied. If you keep track of the current start index, you can implement paging; you can, for example, save the current index in a variable and increment it on each request. Hence the following properties are required when paging the results:
By default, the count function uses the name of the query with the _count suffix. To set a custom name, enter it in the entry field next to the check box.
Dynamic Ordering and Static Ordering:
Sorting of the result set with the dynamic ordering definition evaluated on runtime and static ordering remaining unchanged.
Fetch joins: initialize join entities with the entity's parents with a single select
Fetch joins prevent performance problems that occur when every record is fetched with a separate database select.
You can filter the query results depending on the values in:
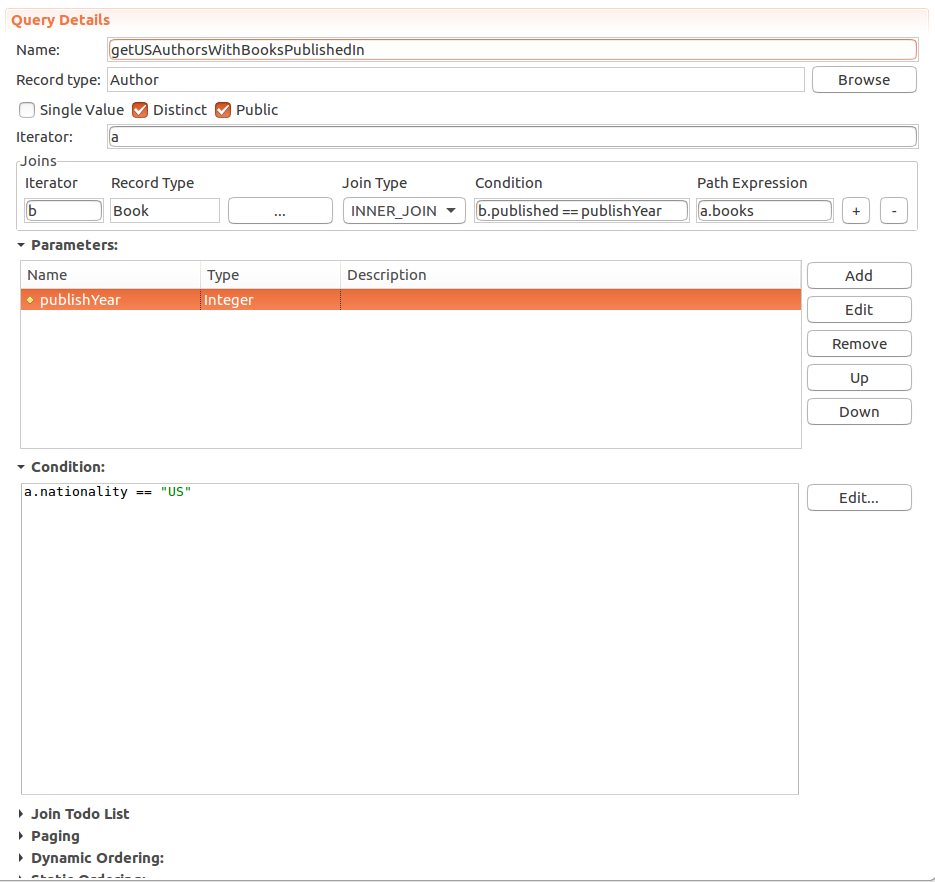
Joins in Queries enable filtering of the Record entries based on related Record data, such as, get Authors who wrote a Book in 1983: in this case you would use an inner join to author's book and check if a book was published in 1983.
You can use joins on Records that are connected to the returned Record with a Data Relationship. Make sure, the end pointing to the related Record is named. Note that joining on a query does not fetch the joined table: the query still returns only the Records of the query return type.
To define a join in your standard query, do the following:
full: all Records that meet the conditions
The query will perform a cross join: it collects the Records and the joined Records, combines each Record with each joined Record, and applies the query condition on the results.
Note: Inner and outer joins are left joins.
Condition (for path expression): condition applied on the join table entities
The condition is useful when the join is an outer join, since it is checked on a smaller set of entities as opposed to being checked on all entities when defined as the query condition. Under these circumstances, the condition can improve performance.
Path expression: path from the iterator Record to the Record for the join
It must return a single instance of its type, or a list or set of instances of such a type.
The path expression must start with one of the iterators, either a join iterator or a shared Record iterator.
To order the entities returned by a standard query, define the list of record properties used for ordering of the result entries: the entities are then ordered according to the values of the first property; if records contain the same value in the property, the second property is used for ordering, etc.
You can define ordering as dynamic or static:
If you define both the static and dynamic ordering, the static ordering takes precedence over the dynamic ordering: if you define static ordering of book records according to their author and dynamic ordering according to their title, the results will be ordered primarily based on their author and only on the next level ordered according to their title.
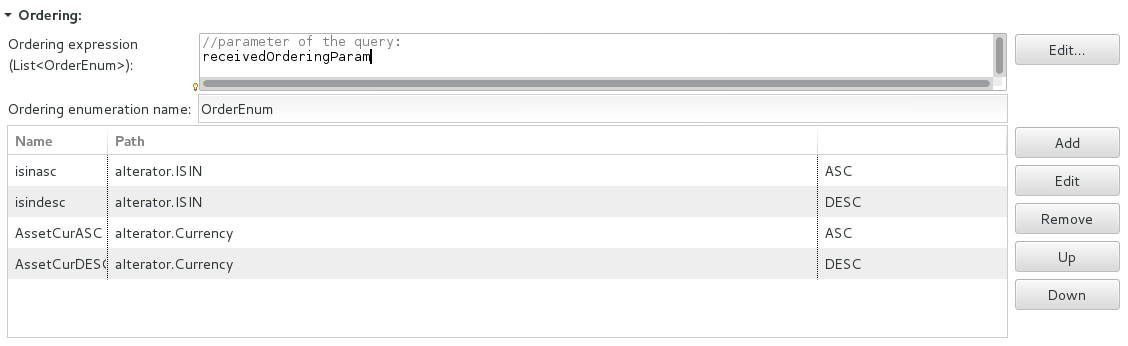
Dynamic ordering defines an ordering expression which returns a list of order-enumeration values. It is evaluated for every query call.
The database query can return the records in a different order on different calls; for example, the ordering expression can use the query parameters, where the incoming parameter holds a list of ordering enumerations.
To define your query to return results ordered based on runtime data, do the following:
<ITERATOR_NAME>.<FIELD_NAME>, for example, book.author. Every path must define its sort order as either ASC to sort the records in the ascending order or DESC to use the descending order.The expression can use the incoming query parameters, where the incoming parameter holds a list of ordering enumerations and must return a list of ordering enumerations.
Example ordering expression
Static ordering of query output relies on a list of ordering paths: each query call uses the same paths for ordering.
To define static ordering of your query, do the following:
The ordering path must define the following:
<ITERATOR_NAME>.<FIELD_NAME>, for example, assetIterator.owner.email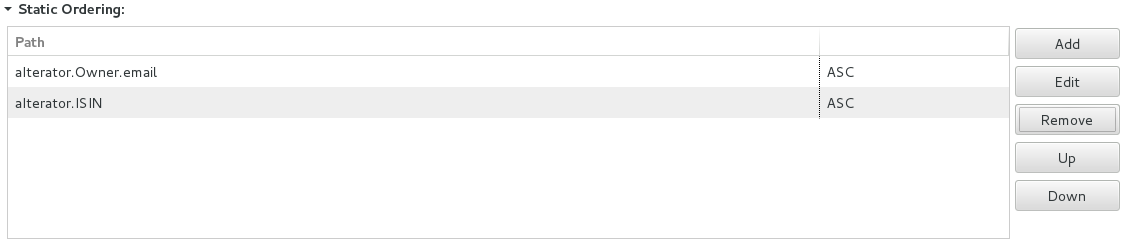
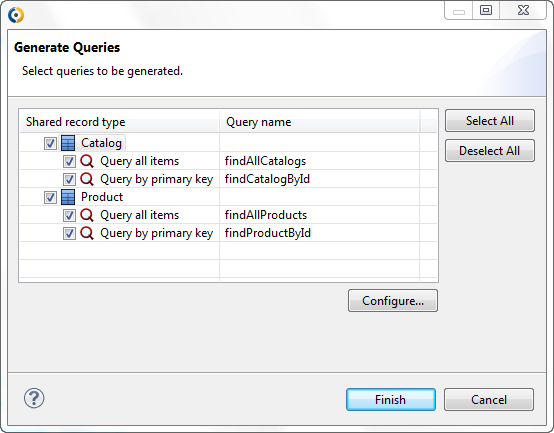
The mechanism for generating queries creates standard queries for shared Records of the Module.
For every shared Record, you can generate queries that return the following:
all entries of the shared Record
The queries are generated as findAll<RECORD_NAME>() queries.
entries of the shared record with a particular ID
The queries are generated as find<RECORD_NAME>ById(ID) queries. The ID Parameter has the data type of the primary key of the shared Record.
Note, that you can re-configure the name format on generation.
To generate the definitions of such queries perform the following steps:
A native query is a named expression that defines an SQL database query. Note that, unlike standard queries, native queries do not rely upon shared records to query the underlying database. This allows you to make use of native database features and possibly secure better performance.
A native query is called from an expression in the same way as a function. When called, the query requests entities based on the defined query string. The results are stored in the defined Row type. If the query returns only the first entity, the entity is returned as an object of the row data type. If the query returns multiple entities, they are returned as a list of the row data type.
A native query defines the following properties:
Result type: type of the return value
The type can be a primitive data type, such as a String, or a non-shared Record.
Single value: amount of the returned values
If true only the first returned value is provided as output; if false, all values are returned as a List of the return type. Note that these might be subject to paging.
Note: Parameter names must be valid identifiers unique within the query.
Example: Mapping and query definitions
- Mapping:
Currency, Price, ISIN- Query:
"SELECT CURRENCY, PRICE, ASSET_ISIN FROM ASSET WHERE CURRENCY=:curr”The CURRENCY will be mapped to Currency, PRICE to Price, and ASSET_ISIN to ISIN of the row type. Note that the order of the defined fields is preserved.
To call a query, use the following syntax: <query_name>(<parameters>)