LSPS Documentation
A data type model is the hierarchy of all records–user-defined data types with an inner structure–with all their relationships in a model.
The purpose of records and their relationships is to define the data structure that accommodates the business data used in your model.
A data type model can contain the following:
A record represents a complex data type, such as, a person, product, service, etc. The structure of a record is defined by a set of record fields of a given data type, for example, a record Persona could have the fields surname, firstName, and dob. The data types of fields should be preferably simple data types.
In situation, where a record requires further structure data, create another record and use a Relationship to connect them.
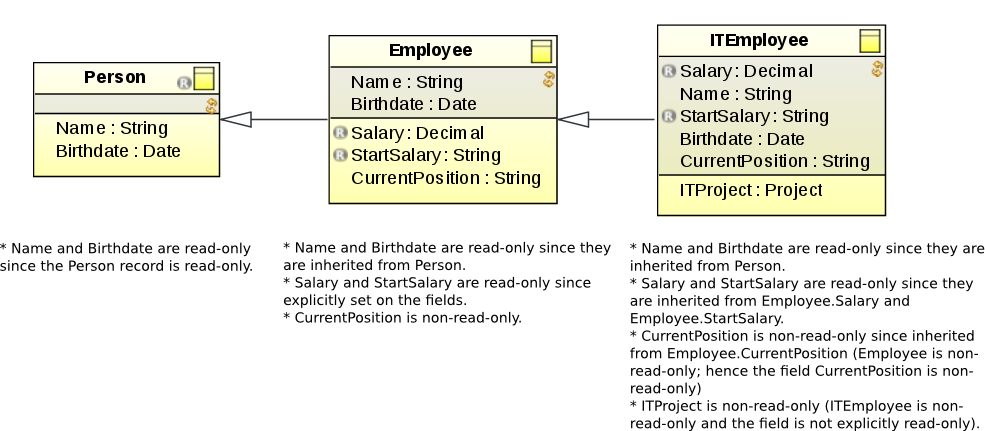
Records can establish inheritance: a record can be a subtype of a record; the subtype record inherits the fields of all its supertype records.
On runtime, a record is used as a blueprint for its instances, which hold the business data: While an Invoice record defines the structure of an invoice, a particular invoice is represented by an instance of the Invoice record. Record instances are created with the new operator; for example, you can create a person record instance of the Person record as new Person("Doe", "John", date(1982, 1, 14)). For further information on the behavior of operators when a record is involved, refer to the Expression Language guide.
Each record can be marked as the following:
system record: System records cannot be instantiated or modified from model instances.
Such operations can be performed only by custom objects implemented in Java in your LSPS Application code.

Allowed record values can be restricted with constraints.
A shared record serves to persist the record instances: each instance of a shared record is persisted in the database and hence survives after their context is destroyed.
A shared record is mapped to a database table:
Make sure your shared record is mapped to the correct table. By default, the name of the target table is based solely on the record name and does not reflect the module name. Therefore, if you define multiple shared records with the same named and you don't change the target table, or schema, they will be mapped to the same table even if they are defined in different modules.
Any readings, modifications, and deletions of shared record instances are immediately reflected in the mapped database entry.
Fetching of record instances is governed by Hibernate's principles and by the transactions of the model instances.
Important: When a field of a shared record is of a different type than Boolean, Integer, Decimal, String, Date, or Enumeration the field must define the space that is reserved in the underlying database column as its BLOB size. The field data is then serialized when stored and must be deserialized when queried. This is considered bad practise: A field of a shared record must not be of type collection, map, record or any other complex type. Use record relationships instead. Neither can a field be of type Closure or Reference since these types are bound to their context on runtime.
For information on the implementation of shared records and the related mapping and fetching mechanisms refer to Process Design Suite User Guide.

An Interface serves to enforce implementation of a set of methods on its child Records. It does not have any Fields or Relationships.
Records that implement the Interface are connected to it with the Realization connector.
An enumeration is a special data type that holds literals which represent the possible values of the enumeration object. The values are called in the form <enumeration_name>.<literal_name>. Since the literals are arranged as a list of values, comparing enumeration literals is based on comparing their indexes: The order depends on the order of the literal as modeled in the enumeration. The comparison operators =, !=, <, >, <=, >= can be used on the literals of the same enumeration type.
Enumerations don't engage in relationships: they cannot be targets or sources of inheritance or data relations.

The record import serves for importing records defined in another resource, such as an imported module or in another data type definition of the current module.
If the record import is an import of a shared record, the following restrictions apply:
Inheritance is an oriented relationship between two records, shared or common, in which the source record is a more specific record of the target record, for example, the Person record as a supertype of the NaturalPerson and LegalPerson records: a subtype is able to substitute its supertype in any operation valid for the supertype.
The subtype record adopts all fields as well as public and protected methods of the supertype Record and the supertype's supertype records, etc.
Inherited methods can be overridden: when overridden, their visibility can be changed only from protected to public.
A inheritance relationship cannot be cyclic, for example, if type T has subtype V, the subtype V cannot have T as its subtype: A record can be final to prevent it from being a supertype.
The read-only setting of field is preserved when inherited, that is, if record A contains a read-only field A and record B is the supertype of record A, then the inherited field remains read-only.
A data relationship establishes a logical connections between two records, such as, employee and company. With a relationship, you can navigate between the records to query and work with such related data easily.
A relationship can be cyclic: the source and target can be the same record. For example, if a company can cooperate with a set of other companies, you can create a relationship with the company record as its source and target and 1:N multiplicity.
Note: Read-only records can only be targets of data relationships, but not their sources. This prevents a possible inconsistency of data.
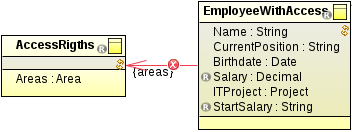 Invalid data relationship between read-only Records
Invalid data relationship between read-only Records
Data relationships define the following:
Navigability of a data relationship end enables you to "move" to the related record. To establish navigability, the respective relationship end must be named: every data relationship must define at least one of its ends' name.
The relationship works both ways equally and properties of the navigations to either end are defined for both ends (they are symmetrical).
Example: The records Author and Book are connected with a relationship: The end pointing to the Book is named "books" so you can navigate from the Author record to the Book record:
heller.books. The relationship end pointing to the Author does not have a name. Therefore, you cannot navigate from a book to its Author.
Single: one record instance
For example, let's assume Sport Shoes and Production Batch records: a pair of shoes is produced as part of only one batch; hence the relationship from the Sport Shoes to the Production Batch has Single multiplicity.
Set: multiple different record instances
In the example, this would be the multiplicity on the relationship end pointing to the Sport Shoes.
For two shared records, the Set multiplicity can define the Order By property with the database column that is used to order the related record instances. If no value is specified, the instances are ordered according to their primary key. For example, if the shared record Person has a navigable Set relationship to the shared record Citizenship and defines the Order by property as countryCode, then the Citizenship record instances fetched as related record instances by the expression Person.citizenship will the ordered according to the countryCode.
Note: If one end defines the List multiplicity and the other end a Single multiplicity, then for every item of the List exactly one item in the other end is available. Such a relationship does not handle situations where one entity is available multiple times in the list.
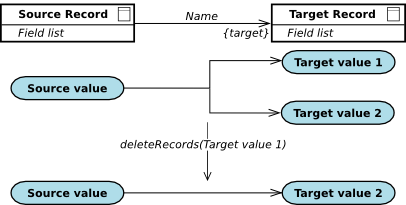
A composition is a "target-is-part-of-source" relationship: the value at the target end cannot exist by itself, that is, without a source value. If the source value is removed, all its target values are removed.
The source end of a composition relationship must be of the single multiplicity: when the value at the source end is deleted, the values at the target end are deleted as well–cascade delete takes place.
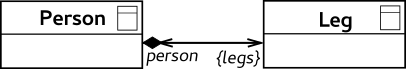
The record instances in a relationship are deleted depending on the relationship multiplicity as follows:
null. 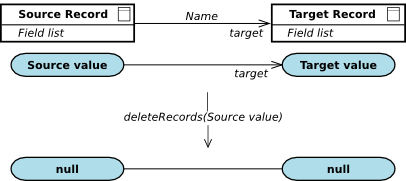
null. 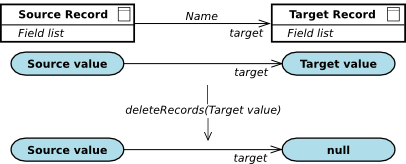
A constraint defines a criterion which a value of a record field or property should meet.
Each constraint defines its constraint type and the Record or Property it applies to. It is the constraint type that defines the semantics of the validation—for the constraint to be met, the value of the Record or property must meet the condition defined in the constraint type. Constraint type can define parameters and it defines an expression with the validation logic which returns validation messages, when the validate value is not allowed. You can define custom constraint types if necessary.
For example, a Persona.name constraint could bind the doesNotContainDigits constraint type to the record field givenName. You could define a constraint type isISBN with a constraint expression that checks if a value is in the ISBN format and then use it in a constraint to bind it to the record field Book.ISBN.
When a record or its property is validated, the validation returns a list of constraint violations with messages from the violated constraints.
A constraint defines the following properties:
ID: unique identifier of the constraint
It is recommended to use IDs in the format <RecordName>.<FieldName>.<ConstraintTypeName>, such as, Book.ISBN.Format, Book.ISBN.NotNull, ISIN.IsNumber, ISIN.HasMinLength, etc.
Tags: expression that results in a list of tags
When validating with tags, a constraint is invoked and checked only if its tags list defined by the tag expression contains at least one of the validation tags. The tag expression can contain tags, and, or, not keywords and parenthesis, for example, MY_TAG1 or (MY_TAG2 and MY_TAG3).
In addition, tags can contain subtags so you can create hierarchical tags: if a tag contains a collection of subtags, the tag is considered the union of its subtags.
Example Tag expression
While a constraint defines which record or property should be validated and whether it should be validated (using tags), it must define also the constraint type with the validation logic that is to be applied, such as, whether it value is not null or is in a format.
Constraint types have the following properties:
Type parameters: type parameters to operate over a parameter that can be of different data types in different calls
The concept is based on generics as used in Java. You can also make a generic data type extend another data type with the extends keyword. The syntax is then <type_param_1> extends <type1>, <type_param_2> extends <type2>.
Parameters: input parameters
The following parameters are provided by default and cannot be deleted:
complex: list of ConstraintViolation objects or their subtype
Complex types allow cascading validation when related records and records fields are validated as part of the record validation. For an example, see the RecordValidity constraint. Example usage is available in Validating a Related Record.
Expression: constraint check expression
If validation is successful, the expression must return null; if it fails, it must return